

12·
2 years agoMost doxxers don’t technically release the information, rather they’ve acquired it and point others to where they’ve acquired it or simply disseminate it further.

Indie iOS app developer with a passion for SwiftUI
Most doxxers don’t technically release the information, rather they’ve acquired it and point others to where they’ve acquired it or simply disseminate it further.
That’s what I’m saying. In most cases the doxxer isn’t the one who originally provided the info, but rather someone who has found the information online via a Google search or something similar.
Only if there’s a risk at incriminating yourself, and if it’s not immediately apparent how you’d run that risk (e.g. you’re a witness that doesn’t have a direct relation to the crime at hand) you’d have to motivate how it could be incriminating.
Isn’t that a little bit of circular reasoning?
If I doxx someone online then it gets indexed by Google, if someone then Google’s the information it stops being doxxing?
I’d assume most doxxing isn’t done by someone who has unique firsthand knowledge (e.g. “Oh I know John, he lives on so and so road”) and instead is done by finding the information online whether via Google or a different public source.
At least in the US, where a ridiculous amount of private information is deemed “public”.

Apologies, it seems DMs are somewhat broken. I’ve found your DM and sent you a reply.
A 100% of $0 is still $0.
There are plenty of instances that are open, but it depends on your definition of “censored” if they are what you seek.
Completely “uncensored” instances are rare if not non-existent because most instances will at least try to adhere to the laws of their jurisdiction and in addition will have some rules in place to keep things running smoothly and pleasant for everyone.
Most big instances are run from the EU so they’ll often have rules regarding hate speech.
Depending on your definition your only options might either be Japanese instances due to less strict laws around certain content or right wing instances, but both will be almost uniformly blocked on other instances.
It means no porn, how much that overlaps with anything remotely considered NSFW is up to the admin and you’d have to ask them.

The individual cashier won’t care, but the manufacturer might, especially if they’re returned as defective because they then make their way back as RMA.
Shops will also stop stocking the item if it stands out because more people return them.
They want to make a profit after all and if they have to discount items as “open box” then they’re losing out on profit, especially since the margins on some of these are already pretty low for retailers.

Apparently if you try to use the USB port it’ll stop after having printed 20 or so pages, telling you you need to setup WiFi and install their bloatware app.
Typically low level attacks such as these is where it starts because they grant access to parts that can be used to learn more about the system as a whole.
This understanding then can be used to find easier to exploit avenues.
A good example of this is the history of exploits on Nintendo hardware.
They almost all started with finding an exploit at the hardware level, which then subsequently lead to finding software exploits and ways to leverage them in an easy way for end users.

The US can look at how other countries, that don’t outright provide free education, do it instead of reinventing the wheel.
Getting rid of the discharge protection is only a small part of it.
It’s more important to set a legal maximum for college tuition for accredited institutions.
Then make any subsidies and funds contingent being accredited.
Lastly make federal loans contingent on enrollment to accredited institutions, with the additional benefit of being able to cap the loan amount at a level correlated to the legal maximum tuition (not to be confused with setting at the tuition level because living expenses need to be taken into account as well).
Make the interest rate sub 1%, because the government shouldn’t profit off of you as it is a service and do away with private middle men that administer the loans, instead establishing a special loan administration agency.
This will have as effect that institutions either get in line or lose all government funds and a significant portion of enrollments.
If you then also manage to uphold a uniform quality level that you regularly inspect at the accredited institutions, you’ll end up with a clear, affordable choice of quality education v. unknown quality education that may or may not be a huge waste of non-publicly provided money.
ETA:
You can even take it a step further and follow more examples from abroad in terms of acceptance.
Where you aim to get to a situation that everyone that applies with the pre-requisite prior education credentials, gets accepted.
The way this is often done abroad is with a centralized application process managed by the government, in which you indicate your top 3 preferred colleges, the portal verifies your prior education (as it’s centrally registered) and then enrolls you in order of preference.
For some studies, like law school, med school and psychology they’ll have more applicants than available spots, and in those cases it’s decided by lottery with slightly weighted chances based on your grade average.
The end result is that the vast majority of people automatically get accepted and the ones that don’t get in via the lottery are almost guaranteed to be placed the following year.
This solves the whole minority/legacy/etc. acceptance debacle, makes applying for schools less like applying for a job with writing essays and stuffing your resume with a bunch of extracurriculars and in the process makes the accredited institutions even more attractive compared to the potential hold outs that keep doing things the old fashioned way.

There’s not much for him to be concerned about currently, given that he is dead.
As for 16 yo Aaron who wrote that list of hot takes in order of controversy, is it really surprising that a kid that developed an opinion of free speech extremism penned that down?
Especially after being inspired by this article as per his own admission?
The article also helps provide context for the time period this was written in.
Simple possession was still a relatively novel concept and simulated CSAM wasn’t criminal yet in the US.
Don’t misconstrue my own position on the matter, I originate from, and was legally trained in, a jurisdiction that criminalizes hate speech, imposing a significantly broader limit on free speech than the US currently does, and I think that’s the better path to take.
So I personally don’t adhere to free speech extremism.
Nevertheless, while not agreeing with his take, I can see the logic that persuaded him.
It’s essentially the facetious version of “Why stop here, why not also ban hate speech/guns/drugs/etc?”
All of those can be argued to be gateways to the harm of others, perhaps even disproportionately children.
To me it reads as him challenging the logic, not condoning the outcome much less the subsequent consequences. Very edgy indeed.
As for those who bring up that he reinstated his blog multiple times and with it this particular post from when he was 16, as a way to posthumously attribute this to a more older adult version of him; I’m not sure it’s that cut and dry.
As a fundamentalist such as himself it could also just be an exhibition of his free speech extremism perhaps combined with an effort to maintain transparency.
After all, it could suggest an eroding of his beliefs on free speech if he would remove it “now” with little benefit to him since the cat’s already out of the bag, even if he disagreed with his former self at the time of restoring the blog.
A better indication of his opinions later in life would be comments that reaffirm the prior expressed beliefs or, if the suspicion is that he practiced what he preached, one would expect this to have come out during the FBI investigation, considering they went through all his data.
Do I think it’s healthy to consider him a hero, or anyone else for that matter?
No not really, if only because the likelihood of heroes having irreconcilable blemishes is extremely high just by the very virtue of their, let’s say, unique thinking producing the things we love about them but also the things that might cause pause in many.

You don’t know Some Software Corp and their world famous website somesoftwarecorp.com?

The proposal is bad enough as it is, but it’s the duplicitous gaslighting BS that really pisses people off.
If they came out and said “We came up with this thing to prevent loss of revenue on ads and prevent LLMs from capturing data” then people would still be against it, but at least it would feel like an honest discussion.
Instead it’s just another page out of Google’s playbook we’ve seen many times already.
For what it’s worth I blame W3C as well.
Their relatively young “Anti-Fraud Community Group” has essentially green lit this thing during meetings as can be seen here:
https://github.com/antifraudcg/meetings/blob/main/2023/05-26.md
https://github.com/antifraudcg/meetings/blob/main/2023/07-07-wei-side-meeting.md
WEI can potentially be used to impose restrictions on unlawful activities on the internet, such as downloading YouTube videos and other content, ad blocking, web scraping, etc.
Did the author of the article come from some dystopian parallel universe?
Well that explains why they did a 180 on their “no AI” rule, which has the mods in a tizzy.
Who knows, maybe it’ll cut back on the toxicity in the sense that you don’t have to interact with toxic people ¯\_(ツ)_/¯
But for iOS you’re forced to use Xcode for implementing certain things like permissions, build and upload.
You can do all that via VSCode as well if you so desire.
Permissions, configurations, etc. are essentially all just XML files and can be edited as such, building, running in simulator and uploading can all be done via CLI.
And if you’re not comfortable doing it via the terminal in VSCode, you can also find some extensions.
Personally as a native dev I don’t know why you’d want to of course, but to each their own.
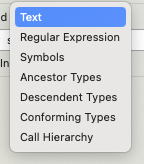
I think you might be misunderstanding what this does.
You did a search for symbol references that contain “User” ignoring cases.
When you do a search for symbol references this way, Xcode will return two things:
And it did just that.
The first three .swift files show references to symbols that contain “User”.
The forth one, User.swift, is in and of itself a symbol that matches the query and has symbols inside itself.
The last one UserViewModel.swift is in itself a symbol as well and all the parts that are nested within that you’ve annotated with underscores and question marks, serve to give you context about the symbol “UserViewModel”, hence the ellipses.
It’s essentially telling you “Hey I’ve found this symbol UserViewModel, it starts with a var named username, has a bunch of stuff following that (i.e. …) then has an extension, then some more stuff (i.e. …) and then ends”.
Without knowing what’s inside UserViewModel.swift I can’t tell if it goofed with giving you a typical declaration, but that doesn’t change the fact that its trying to give you context about a valid search result, the symbol UserViewModel, so that you can figure out if that’s the one you’re looking for.
Keep in mind that variables are considered symbols as well, but in this instance I don’t think that’s what happened here, otherwise it would’ve been marked with a P instead of a C.
If this is not desired behavior then I suggest you switch from “Containing” to “Matching Word” or instead consider using the search bar at the bottom of the Symbol Navigator.
Another option, if you’re searching while going through code, is to right click on the symbol in your code and click Find > Find Selected Symbol in Workspace.
Lastly it might be an idea to go over the Xcode documentation as a refresher. This would be a good starting point.
That said, Apple clearly feels that things can be improved by clarifying, because in the current Xcode beta they’ve changed the option label from References to Symbols (and added a few more options).



{kind=link}
Cue the nuclear shills that will handwave away any legitimate concern with wishful thinking and frame the discussion as solely pro/anti fossil, conveniently pretending that renewables don’t exist.
ETA:
Let’s look at some great examples of handwaving and other nonsense to further the nuclear agenda.
Here @[email protected] brings up a legitimate concern about companies not adhering to regulation and regulators being corrupt/bought *cough… Three Mile Island cough*, and how to deal with that:
So of course the answer to that by @[email protected] is a slippery slope argument and equating a hypothetical disaster with thousands if not millions of victims and areas being uninhabitable for years to come, with the death of a family member due to faulty wiring in your home:
Then there’s the matter of misleading statistics and graphs.
Never mind the fact that the amount of victims of nuclear disasters is underreported, under-attributed and research is hampered if not outright blocked to further a nuclear agenda, also never mind that the risks are consistently underreported, lets leave those contentious points behind and look at what’s at hand.
Here @[email protected] shows a graph from Our World in Data that is often thrown around and claims to show “Death rates by unit of electricity production”:
Seems shocking enough and I’m sure in rough lines, the proportions respective to one another make sense to some degree or another.
The problem however is that the source data is thrown together in such a way that it completely undermines the message the graph is trying to portray.
According to Our World in Data this is the source of the data used in the graph:
Fossil fuel numbers are based on this paper which starts out by described a pro-nuclear stance, but more importantly, does a lot of educated guesstimating on the air-pollution related death numbers that is straight up copied into the graph.
Sovacool is used for solar and wind, but doesn’t have those estimates and is mainly limited to direct victims.
Nuclear based deaths is based on Our World in Data’s own nuclear propaganda piece that mainly focuses on direct deaths and severely underplays non-direct deaths.
And hydropower bases deaths is based on accidents.
So they mix and match all kinds of different forms of data to make this graph, which is a no-no. Either you stick to only accidents, only direct deaths or do all possible deaths that is possibly caused by an energy source, like they do for fossil fuels.
Not doing so makes the graph seem like some kind of joke.